

As we move into 2025, the flood of PDF files in business and professional life shows no sign of slowing down. Extracting valuable information from this sea of documents is becoming more difficult and time-consuming for everyone. If you need to extract data from pdf files quickly and accurately, outdated methods just won’t cut it anymore. In this article, you’ll discover seven smart and efficient ways to extract data—ranging from simple manual steps to advanced AI-powered tools. Get ready for practical tips and expert strategies that will help you save time, boost accuracy, and streamline your workflow.
Understanding PDF Data Extraction in 2025
As we navigate an era defined by digital transformation, PDFs have become the backbone of information exchange in both business and academia. Contracts, invoices, research papers, and compliance documents are routinely saved in PDF format, valued for their universal compatibility and robust security. In fact, industry estimates reveal that over 2.5 trillion PDFs are created globally each year.
However, this ubiquity brings a paradox. While PDFs standardize document sharing, their fixed layout often complicates efforts to extract data from pdf files, especially as organizations encounter more scanned, image-based, and multi-format documents.

The Evolving Role of PDFs in Business and Academia
The PDF format is a double-edged sword. On one hand, its ability to preserve formatting, prevent unauthorized edits, and ensure cross-platform reliability makes it indispensable. On the other, extracting structured information is rarely straightforward.
PDFs can contain a mix of text, tables, images, and even embedded handwritten notes. This complexity has grown as more documents are digitized using scanners or mobile devices, resulting in image-based files that standard text selection tools cannot process. As a result, organizations increasingly need to extract data from pdf documents with precision and efficiency.
Challenges in Extracting Data from PDFs
Extracting data from pdf files involves navigating a range of technical obstacles. Data can be structured (such as tables or forms) or unstructured (freeform text, images). Common hurdles include:
- Tables with merged cells or irregular layouts
- Embedded images or scanned handwriting
- Password-protected or locked documents
- Inconsistent formatting across pages
Traditional copy-paste methods often fail, leading to errors, lost formatting, and wasted time. For businesses handling hundreds or thousands of documents, manual review simply cannot scale. Accuracy, speed, and the ability to handle diverse layouts are now essential in any solution designed to extract data from pdf files. For a deeper understanding of these technical challenges, refer to this Data extraction overview.
The Need for Smart Solutions in 2025
Given the growing complexity and sheer volume of PDFs, organizations are turning toward automation, AI, and cloud-based solutions. These technologies not only accelerate the ability to extract data from pdf files but also address regulatory and privacy concerns by offering advanced security features.
For example, financial analysts use AI-powered tools to process thousands of invoices automatically. Legal teams rely on automated extraction for due diligence, while researchers parse academic journals for meta-analysis. As regulatory frameworks tighten, smart solutions ensure compliance without compromising productivity.
The landscape of PDF data extraction is rapidly evolving, and adopting the right strategies is crucial for staying competitive and compliant.
7 Smart Ways to Extract Data from PDF in 2025
Extracting data from pdf files is no longer a one-size-fits-all task in 2025. With document complexity on the rise, professionals require a toolkit of methods to tackle everything from simple invoices to multi-format reports. Below, we break down seven smart, efficient strategies—each tailored to specific document types and business scenarios.
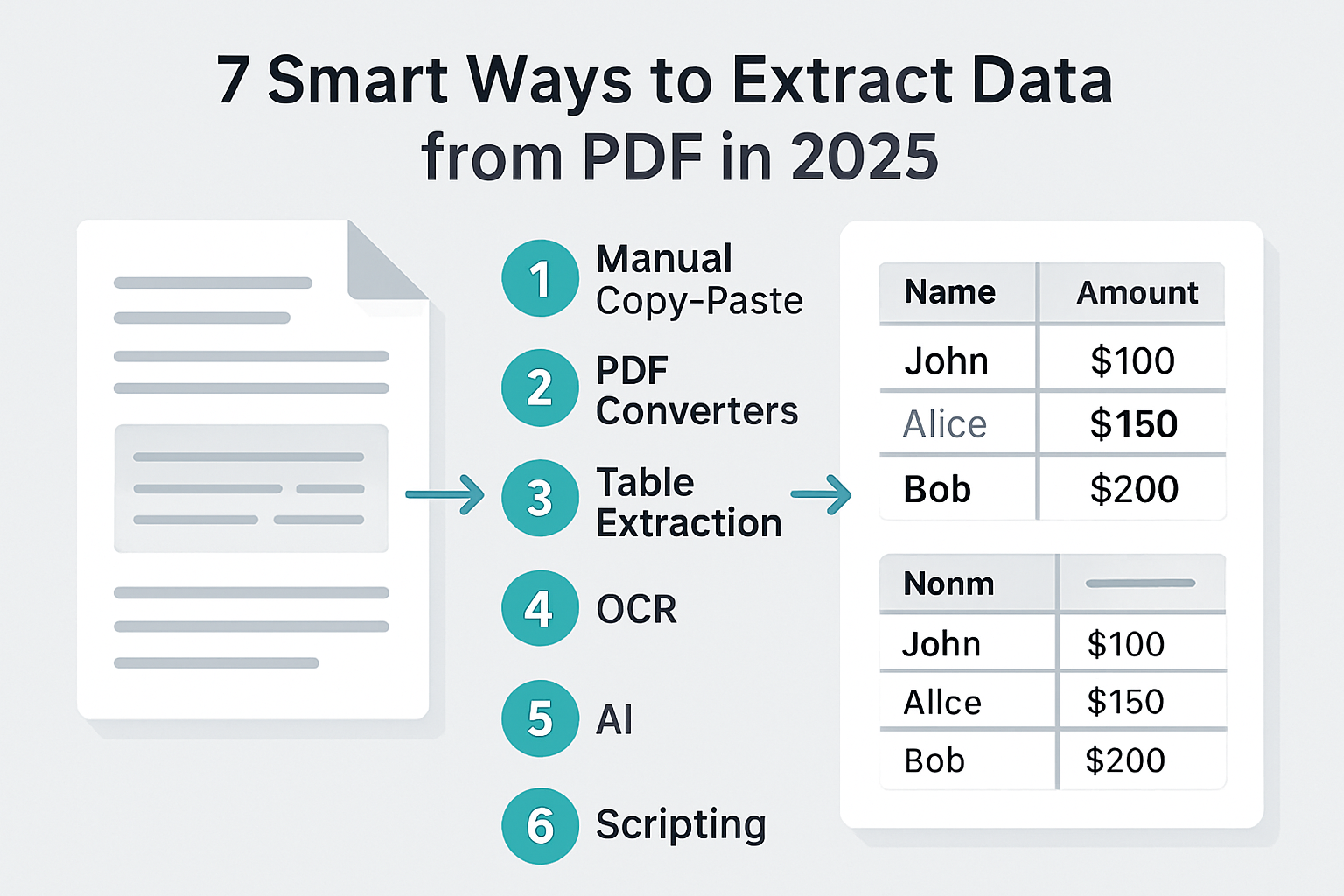
1. Manual Copy-Paste for Simple Documents
For straightforward documents, nothing beats the simplicity of manual copy-paste to extract data from pdf files.
Step-by-step process:
- Open your PDF in a reader (Adobe Acrobat, Foxit, or browser).
- Select the text you need.
- Copy and paste it into your destination (Excel, Word, Google Sheets).
Pros:
- Zero cost
- No special software required
- Complete control over selection
Cons:
- Labor-intensive for multiple or lengthy documents
- Error-prone, especially with complex layouts
- Not scalable for high-volume tasks
Example:
Extracting client names and addresses from a single-page invoice.
Tips to reduce errors:
- Use modern PDF readers with enhanced selection tools.
- Double-check formatting after pasting.
While this method is limited, it remains an essential option to extract data from pdf when dealing with short, text-based documents.
2. Using Built-in PDF Converter Tools (e.g., Adobe Acrobat, SmallPDF)
Converter tools streamline the process to extract data from pdf by transforming files into editable formats like Word, Excel, or CSV.
How it works:
- Upload your PDF to the chosen tool.
- Select the desired output format (e.g., Excel).
- Download and review the converted file.
Popular tools:
- Adobe Acrobat (paid, robust features)
- SmallPDF (freemium, web-based)
- PDF2Go
Pros:
- Preserves most formatting
- Supports batch conversion
- Quicker than manual copy-paste
Cons:
- May misinterpret tables, images, or complex layouts
- Some features locked behind paywalls
- Struggles with scanned or image-based PDFs
Example:
Converting a multi-page financial report to an Excel spreadsheet in minutes.
Accuracy rates:
Text-based PDFs can reach up to 90% accuracy, but this drops with more complex files.
To extract data from pdf efficiently, always review the output for errors and formatting issues.
3. Extracting Tabular Data with Specialized Tools (e.g., Tabula, Excalibur)
When your priority is to extract data from pdf tables, specialized tools like Tabula and Excalibur shine.
How to use:
- Upload your PDF to the tool.
- Highlight the tables you want to extract.
- Export the data in your preferred format (CSV, XLSX).
Pros:
- High accuracy for structured tables
- Open-source options available
- User-friendly interfaces
Cons:
- Not suitable for scanned or image-based PDFs
- May require minor technical setup
Example:
Extracting procurement history tables from an annual report.
Comparison Table:
| Tool | Cost | Table Accuracy | Format Support |
|---|---|---|---|
| Tabula | Free | High | CSV, XLSX |
| Excalibur | Free/Web | High | CSV, XLSX |
To extract data from pdf tables, these tools are indispensable, especially for researchers and analysts.
For deeper insight into methods, see this table extraction techniques resource.
4. Optical Character Recognition (OCR) for Scanned and Image-based PDFs
OCR technology is essential when you need to extract data from pdf documents that are scanned, photographed, or image-based.
What is OCR?
OCR (Optical Character Recognition) converts images of text into machine-readable data.
Top tools:
- Adobe Acrobat
- PDFelement
- Microsoft Lens
- CamScanner
Pros:
- Can process printed and handwritten text
- Unlocks data from non-searchable PDFs
- AI enhancements boost accuracy
Cons:
- Accuracy depends on scan quality
- May require manual review for errors
- Struggles with poor handwriting or low-resolution scans
Example:
Digitizing handwritten consent forms for medical research.
Tip:
Modern AI-powered OCR solutions achieve over 95% accuracy for clear scans, making it a reliable way to extract data from pdf files that aren't text-selectable.
5. AI-powered Data Extraction Solutions (e.g., KlearStack, AWS Textract, Google Document AI)
As document complexity increases, AI-powered platforms have become the gold standard to extract data from pdf files at scale.
How it works:
- Combines OCR, machine learning, and NLP for advanced field detection.
- Supports bulk processing and template recognition.
- Integrates easily with business systems and cloud workflows.
Leading platforms:
- KlearStack
- AWS Textract
- Google Document AI
Pros:
- Handles diverse document types and complex layouts
- High automation and scalability
- Supports real-time processing and integrations
Cons:
- Higher cost, often subscription-based
- Requires setup and initial training
- Best suited for enterprises or frequent users
Example:
Automatically extracting data from hundreds of invoices or contracts each month.
Want to compare leading options?
Check out this AI-powered PDF extraction tools comparison for a detailed look at efficiency and accuracy.
For organizations needing to extract data from pdf at scale, AI-driven solutions are the most efficient and future-proof choice.
6. Scripting and Automation with Programming Languages (e.g., Python, Node.js)
Developers and data professionals often use scripting to extract data from pdf files in bulk or as part of automated workflows.
Popular libraries:
- Python: PyPDF2, pdfplumber, PDFMiner
- Node.js: pdf-parse
Pros:
- Full customization and control
- Batch processing capabilities
- Free, open-source, and strong community support
Cons:
- Requires programming knowledge
- Maintenance and troubleshooting can be time-consuming
Example:
A Python script to extract procurement fields from a folder of PDFs:
import pdfplumber
for file in pdf_files:
with pdfplumber.open(file) as pdf:
for page in pdf.pages:
text = page.extract_text()
# process text
This approach allows you to extract data from pdf documents efficiently, especially for recurring or large-scale tasks.
7. Outsourcing Data Extraction to Professional Services
For organizations lacking time or expertise, outsourcing is a practical way to extract data from pdf files, especially at scale.
How it works:
- Hire vendors or freelancers via platforms like Upwork, Fiverr, or specialized BPO providers.
- Provide clear instructions and sample documents.
- Receive extracted data in your desired format.
Pros:
- Offloads manual work
- Scalable for large or complex projects
- Access to specialized skills
Cons:
- Data privacy concerns
- Variable quality depending on provider
- Ongoing costs for repeated projects
Example:
Outsourcing the extraction of scanned receipts for company expense management.
Tips:
- Vet providers for security and reliability.
- Use NDAs and secure file transfer protocols.
When you need to extract data from pdf in high volumes but lack internal resources, outsourcing offers flexibility—just ensure proper vetting and data protection measures are in place.
Comparing the 7 PDF Data Extraction Methods
Selecting the right approach to extract data from pdf files is crucial in 2025. Each method comes with unique strengths and limitations, making it essential to match the solution to your actual needs. Let’s break down how these methods stack up across key decision factors.
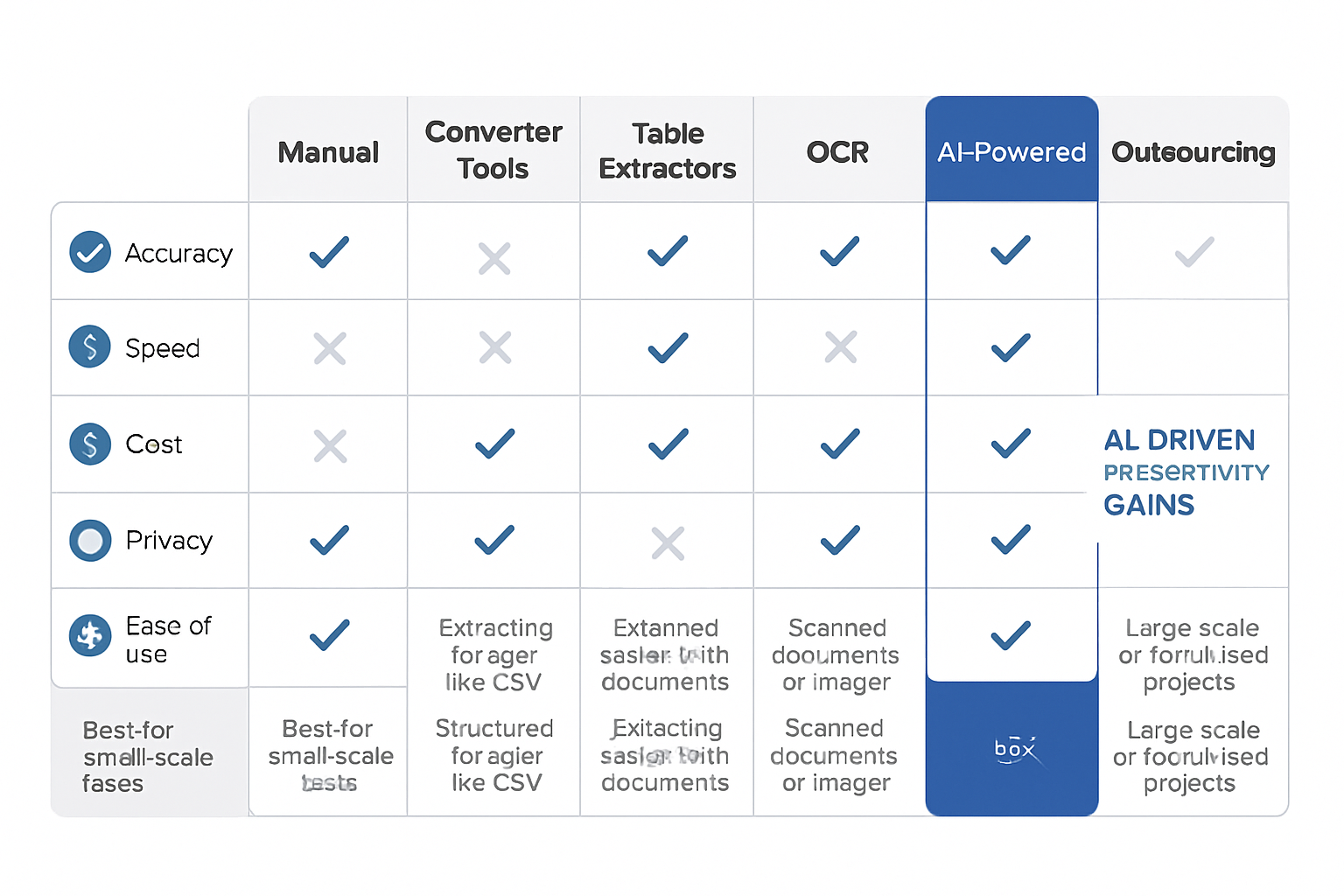
Criteria for Evaluation
When you extract data from pdf documents, consider these five critical criteria:
| Method | Accuracy | Speed/Scalability | Cost | Privacy/Security | Ease of Use |
|---|---|---|---|---|---|
| Manual | Moderate | Low | Free | High | Easy |
| Converter | High (text) | Medium | Freemium/Paid | Medium | Easy |
| Table Tools | High (tables) | Medium | Free/OpenSrc | Medium | Moderate |
| OCR | High (clear) | Medium | Freemium/Paid | Medium/Low | Moderate |
| AI-powered | Very High | High | Paid | Varies | Moderate |
| Scripting | High | High | Free | High | Hard |
| Outsourcing | Variable | High | Paid | Low/Variable | Easy |
Accuracy is highest with AI-powered and well-trained OCR solutions, especially for complex layouts. Manual methods are accurate for small, simple jobs, but are not practical for volume or intricate documents.
Speed and scalability favor AI, scripting, and outsourcing. Manual and converter tools are best for occasional or small-scale tasks. Privacy and security are paramount, especially with sensitive data. For detailed guidance on evaluating trust and security in extraction tools, see the Buyer trust signals checklist.
Cost varies widely—manual and scripting solutions can be free, while AI platforms and outsourcing incur ongoing expenses. Ease of use ranges from simple drag-and-drop interfaces to technical scripting requiring programming expertise.
Real-World Use Cases and Recommendations
For small businesses needing to extract data from pdf files occasionally, manual or converter methods are sufficient. Researchers and academics often benefit from table extraction tools and open-source scripting for structured data.
Enterprises with high document volumes or complex layouts should rely on AI-powered extraction or automated scripting to maximize efficiency. Legal and financial teams handling sensitive or bulk documents may turn to vetted outsourcing services, provided strict security protocols are enforced.
Combining methods is common: for example, using OCR to digitize scanned forms, then leveraging scripting or AI to extract structured data. This hybrid approach addresses both accuracy and scalability.
Key Takeaways from Competitor Insights
AI-driven platforms like KlearStack demonstrate that you can extract data from pdf documents at scale, reducing processing costs by up to 80% and increasing productivity fivefold. While manual extraction remains relevant for simple tasks, it cannot compete with the automation and reliability of modern solutions.
Ultimately, the best strategy is to match your extraction method to the complexity, volume, and sensitivity of your documents. Regularly validate results and adapt your workflow as technology evolves, ensuring your process to extract data from pdf files remains both efficient and secure.
Best Practices and Tips for Efficient PDF Data Extraction in 2025
Extracting information from digital documents is evolving rapidly, and organizations that want to extract data from pdf files efficiently in 2025 need to adopt proven best practices. The right approach can save hours, reduce errors, and ensure your workflows remain compliant and secure.
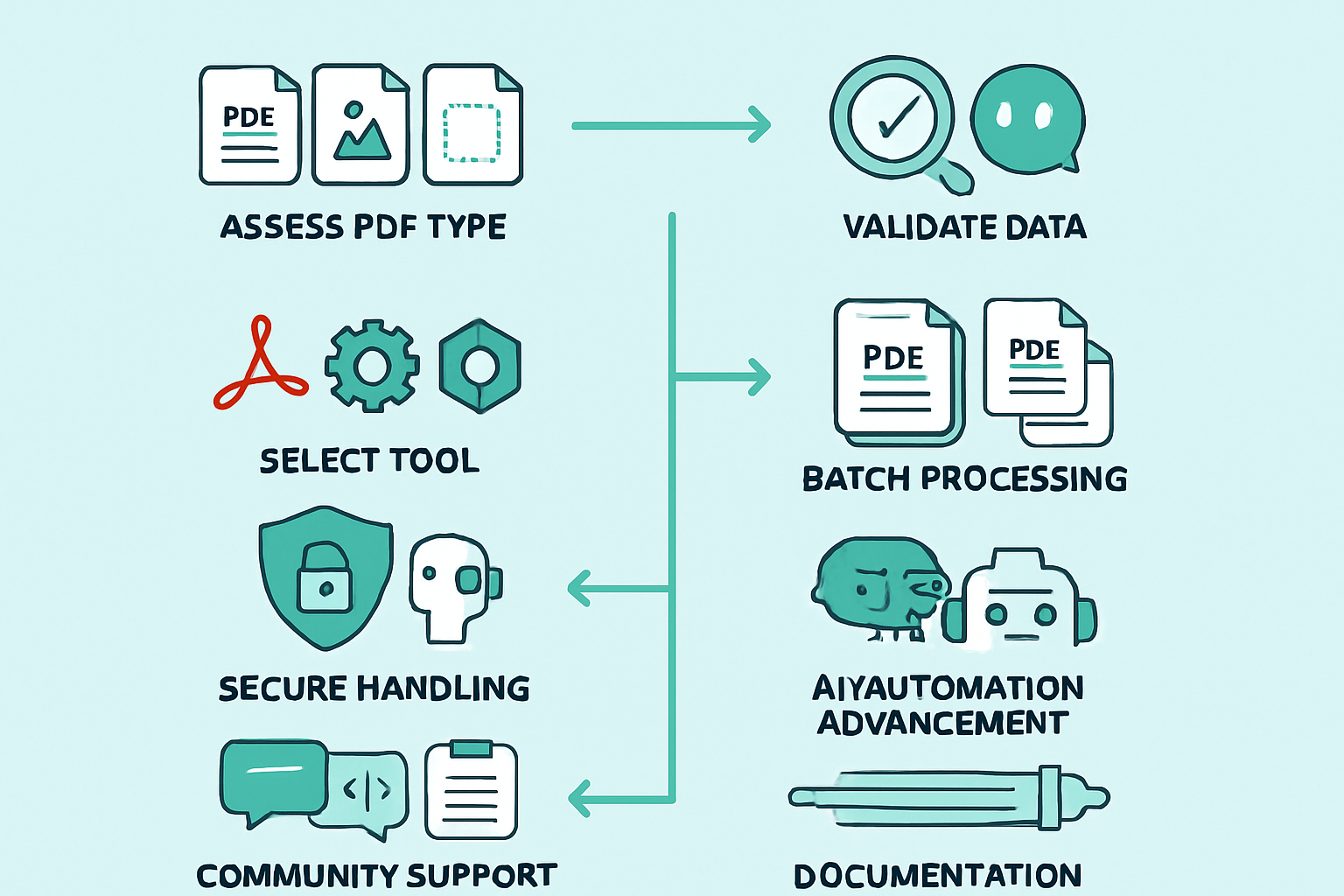
Assess Your PDF Type First
Before you extract data from pdf files, identify the document’s nature. Is it text-based, scanned, image-heavy, or a mix? Knowing this helps you choose the right extraction tool and method. For example, a simple text-based PDF can be handled manually, while a scanned document requires OCR or AI-powered solutions.
Match Tools to Task Complexity
Don’t overcomplicate simple tasks. Use basic converter tools or manual copy-paste for short, straightforward files. For complex layouts or tables, specialized extraction software or enhanced PDF text extraction techniques may be necessary to achieve higher accuracy and handle segmentation challenges. Always align the tool’s capabilities with your document’s structure.
Validate and Review Extracted Data
No matter how advanced your solution, always validate the results. Spot-check samples to ensure accuracy after you extract data from pdf documents. Automated tools and AI can make mistakes, especially with complex layouts or low-quality scans, so manual review remains essential for critical data.
Batch Processing for Efficiency
When working with high volumes, leverage batch processing features in your chosen platform. This can dramatically speed up the process and minimize repetitive manual work. Many modern solutions provide bulk import/export capabilities, streamlining how you extract data from pdf files across entire repositories.
Secure Handling of Sensitive Data
Data privacy is paramount. When you extract data from pdf files containing confidential information, use on-premises tools or trusted cloud platforms with robust encryption and access controls. Always vet third-party vendors for their security standards, and ensure sensitive files are transferred securely.
Stay Ahead with AI and Automation
The landscape is rapidly shifting toward automation and AI-driven platforms. Solutions like the OdysseyGPT platform offer advanced document processing features, saving time and boosting accuracy for even the most complex extraction tasks. Regularly review emerging tools to keep your processes efficient and future-proof.
Leverage Community Support and Document Your Workflow
Open-source communities are invaluable for troubleshooting and optimizing your extraction process. Participate in forums, share scripts, and stay updated on the latest developments. Finally, document your workflow step by step. This ensures repeatability, compliance, and easier onboarding for new team members.
Adopting these best practices will help your organization extract data from pdf files accurately, securely, and efficiently in 2025. Proactive strategy and the right tools are the foundation of successful PDF data extraction.
Frequently Asked Questions About PDF Data Extraction
Extracting data from PDF files is a critical task for many professionals in 2025. Below, we answer the most common questions to help you efficiently extract data from pdf documents and avoid common pitfalls.
What is the most accurate way to extract data from PDFs?
The most accurate way to extract data from pdf files is by using AI-powered and OCR solutions. For clean, text-based documents, AI-enhanced OCR tools can achieve over 95% accuracy. Manual methods may be precise for small tasks but do not scale well. For complex layouts or large volumes, intelligent automation is the best choice.
Can I extract data from scanned or handwritten PDFs?
Yes, you can extract data from pdf files that are scanned or handwritten using advanced OCR and AI tools. While printed text is usually recognized accurately, handwriting and low-quality scans can be challenging. AI-based OCR solutions continue to improve but may still require manual review for best results.
Are there free tools for PDF data extraction?
Several free and open-source tools can help you extract data from pdf documents. Popular options include Tabula for tables, PyPDF2 for text, and SmallPDF for basic conversions. These tools are suitable for basic needs and offer a no-cost entry point for most users.
How do I handle sensitive or confidential PDF data?
When you extract data from pdf documents containing sensitive information, prioritize security. Use on-premises tools or trusted vendors with robust privacy protocols. If integrating extraction into a web platform, consider reviewing Core Web Vitals for B2B sites to ensure your workflow remains secure and efficient.
What is the best method for extracting tables from PDFs?
The best way to extract data from pdf tables is to use specialized tools like Tabula or scripting libraries such as pdfplumber. These solutions convert tables into structured formats, making analysis and reporting much easier. For highly complex tables, custom scripting may be required.
How can I automate PDF data extraction for large projects?
To automate and extract data from pdf files at scale, consider AI-powered platforms, scripting with Python or Node.js, or outsourcing to professional services. Automation enables greater speed and consistency, especially when handling high volumes or repetitive tasks.
What are common pitfalls to avoid?
Common mistakes when you extract data from pdf files include over-reliance on manual methods, failing to validate extracted data, and neglecting security protocols. Always choose the right tool for your document type and double-check results for accuracy.
If you’re ready to move beyond manual copy-paste and tap into smarter, more efficient ways to handle your PDFs, now is the perfect time to explore what advanced AI platforms can do for you. Imagine effortlessly extracting, structuring, and analyzing information from even your most complex documents—saving hours and reducing errors along the way. OdysseyGPT is designed for professionals just like you who want to transform static files into actionable knowledge. Curious to see how it works in your own workflow? Start free trial and experience the next level of PDF data extraction for yourself.